What Separates BetBot from Every Other Betting Service

Why most "AI-powered" betting services aren't
The sports betting industry is crowded with services claiming an edge. Most of them are built on the same foundation: a team of human analysts, historical statistics models, and editorial intuition packaged into a newsletter or app. Some now claim to use "AI" — but in most cases that means a regression model trained on historical outcomes, or a language model that generates generic game previews from a template.
BetBot is something categorically different. Here's what actually separates it.
Frontier AI at the core, not as a gimmick
BetBot runs on Claude — Anthropic's frontier large language model, currently using Claude Sonnet. This is the same class of model that tops reasoning and analysis benchmarks across the board. It doesn't predict outcomes from historical averages. It reads, reasons, and synthesizes — the same way a sharp analyst would.
The difference matters because the most valuable information in sports betting is almost never in a box score. It's in the beat reporter's notebook published at 11 PM the night before a game. It's in a coach's press conference answer that reveals rotational adjustments. It's in the pattern of back-to-back games, travel schedules, and motivation mismatches that don't appear in any dataset. Frontier language models are uniquely capable of processing this kind of unstructured, contextual, time-sensitive information and drawing meaningful conclusions from it.
Traditional handicapping services handle this through human labor — a network of analysts who read articles, watch games, and apply subjective judgment. That's slow, expensive, and doesn't scale. A frontier AI model does the same cognitive work autonomously, faster, and across every game simultaneously.
Agentic tool looping: AI that acts, not just answers
The second — and more significant — differentiator is how BetBot actually uses AI. Most AI-powered products are question-answer systems: you give the model information, it generates a response.
BetBot uses an agentic tool-use loop. When a game approaches, the Research Agent isn't handed a pre-packaged dataset and asked to summarize it. It's given a goal and a set of tools — web search, a page fetcher, a database writer — and it pursues that goal autonomously. It decides what to look for, executes searches, visits articles, reads content, judges relevance, and writes down what matters. All without human direction.
A single research run typically involves 10–15 tool calls:
Search for [team] injury updates →
Read ESPN injury report →
Search for [player] practice status →
Read beat reporter's notebook →
Write research entry: injury/availability →
Search for [team] recent form →
...
The agent adapts in real time. If a search result suggests a key player is questionable, it digs deeper into that angle rather than moving on. If a site is behind a paywall, it pivots to another source. This kind of dynamic, goal-directed behavior is only possible with a true agentic architecture — and it produces research that is meaningfully more comprehensive and current than anything a scheduled data pipeline could deliver.
BetBot also runs a second research pass three hours before tip-off, specifically to capture last-minute injury designations and lineup changes that move lines. This late-window run feeds directly into pick generation, ensuring the final recommendation reflects the most current available information.
Persistent data storage: memory across every run
Agents without memory repeat themselves. BetBot is built around a PostgreSQL persistence layer that gives the system continuity across every research run, every game, and every season.
The database design reflects how good analysts actually think about games. There are two distinct layers of research:
Season Baseline — Deep-context profiles for every team, covering coaching philosophy, roster strengths and weaknesses, scheduling patterns, and situational tendencies. These are built at the start of the season and updated on every research run. When the agent learns something new about a team — a shift in offensive scheme, the emergence of a bench player, a losing streak that reveals defensive vulnerabilities — it writes that to the season baseline so it's available for every future game.
Game-Specific Research — Time-sensitive analysis tied to a specific matchup: injury availability, current form, rest advantages, travel schedules, motivational context. This layer is built fresh for every game and reflects information that was current hours before tip-off.
The Pick Agent receives both layers simultaneously before generating a recommendation — the same combination that sharp bettors spend hours assembling manually.
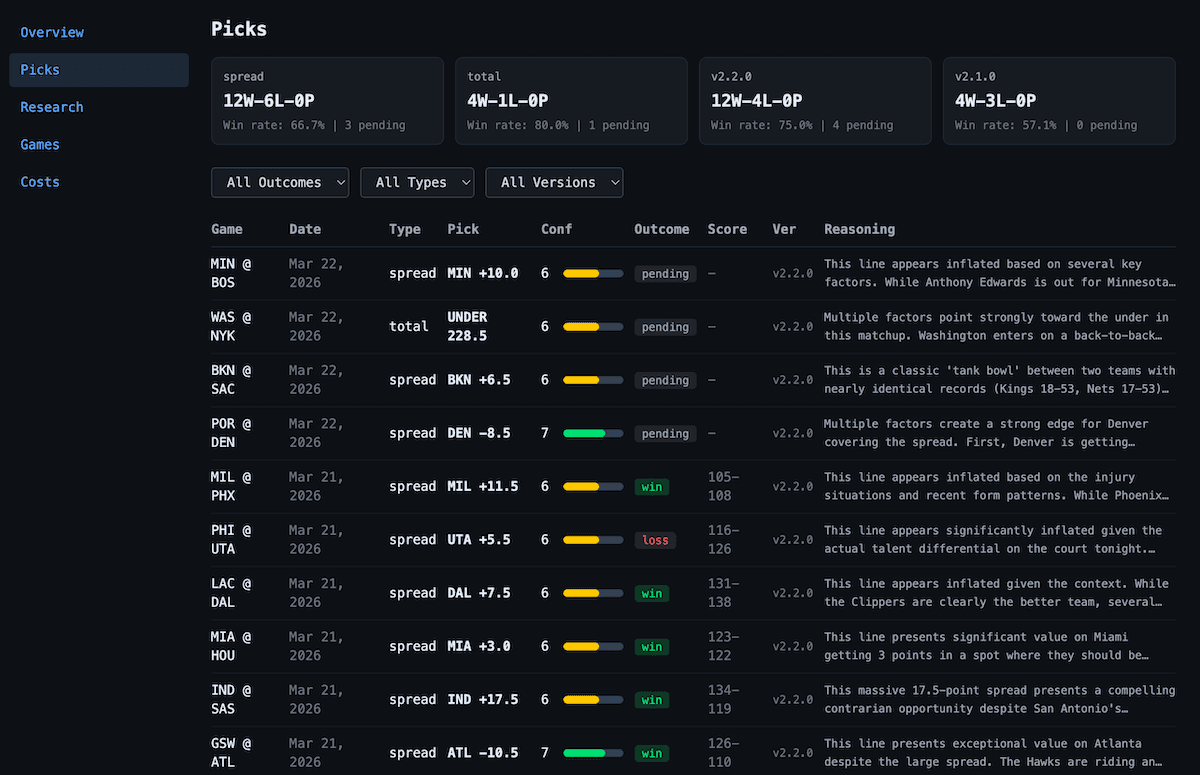
This architecture also enables something most services can't offer: a verifiable, unedited track record. Every pick is stored with a timestamp, the full reasoning, the confidence score, and the outcome. Outcomes are graded automatically after games complete. Not a curated highlight reel of wins — an honest record of every call the system has ever made.
How the pieces compound
Each of these advantages multiplies the others.
A frontier AI model is powerful, but without agentic tool looping it's limited to reasoning over whatever you hand it. Agentic looping is powerful, but without persistent storage the agent starts from scratch every time and can't accumulate knowledge. Persistent storage is valuable, but without a frontier model to make sense of what's stored, it's just a database.
Together, they create a system that:
- Learns over time — Season baseline entries update as the agent encounters new information. A team that starts the season with a strong bench but sees injuries accumulate will have that shift reflected in its baseline
- Reasons across signals — The Pick Agent weighs injury impact, rest advantages, recent form, situational factors, and narrative context simultaneously — not a formula, but genuine reasoning about the relative weight of different signals in each specific game
- Scales without degrading — A human analyst can deeply research a handful of games per day. BetBot can run full research cycles on every NBA game simultaneously, with no drop in quality as volume increases
- Improves automatically — Because pick generation is driven by the underlying Claude model, every time Anthropic releases a more capable model, BetBot's output quality improves. The infrastructure stays the same; only the model version changes
The transparency advantage
Beyond the technical architecture, BetBot is designed around a principle that traditional handicapping services have strong incentives to avoid: full transparency.
The dashboard shows every pick ever made, with outcomes. It shows the full reasoning behind each recommendation. It shows the confidence score assigned by the agent. It shows token usage and estimated cost per run. Subscribers aren't asked to take BetBot's track record on faith — the data is there, unedited, win or loss.
That kind of accountability is only possible when an automated system generates and stores every output consistently. It's one of the things that only an AI-native architecture can credibly offer.
If you're interested in following BetBot's picks, follow me on X at @10xdevdotio for daily posts.
At 10xDev, we build agentic AI systems for businesses that want to automate real, complex workflows — not just generate text. If you want something like this built for your use case, get in touch.